Convolutional Neural Networks
So far, our neural networks have been fully connected (dense). Each unit in a hidden layer has been connected to every unit in the next layer. This doesn't allow the neural network to learn from spatial structures in the images (or audio or some other data with spatial information.) This is where convolutional layers come into play!
Terminology detail: when we do not include kernel flipping, the proper term would be cross-correlation instead of convolution. You will see this term used in some math-focused sources. Neural network tutorials and frameworks usually always use the term convolution instead.
Kernel
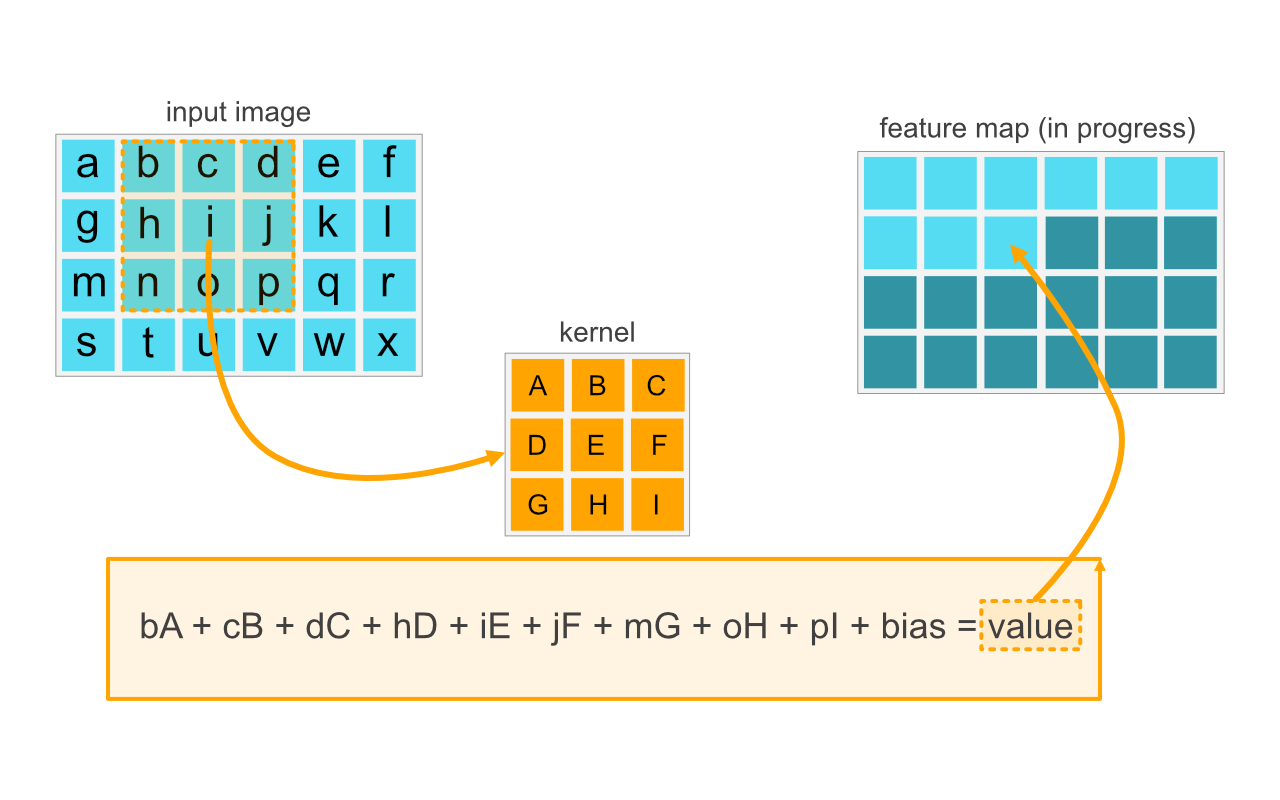
A key element in convolution is a kernel. A kernel is a 2D-matrix, usually a small square with an odd side length. Typical kernel sizes are thus 3x3, 5x5, 7x7, 9x9. The output of this is called a feature map.
The process itself is simple. Imagine that the convolution starts at top-left corner of the input image (image[0,0]), does an element-by-element matrix multiplication (np.multiply), followed by sum (np.sum), and places the value to: feature_map[0,0]. This process is repeated for all pixels of the input image. In the example image above, you can see the process visualized so that pixel values are represented with alphabets. The center of the kernel is at the location of letter "i" and the surrounding 3x3 area is being computed.
Note: If you look at the example closely, you will notice that in the input image location a (top-left corner) the kernel would be partially outside of the image area. Thus, kernel locations [A, B, C, D, G]would have no input value. The same applies to all edge and corner pixels. There are various ways to handle this problem, including padding the image with zeros, or using only valid locations (which will reduce the dimensions of the features map).
You might be wondering what the end result of this might look like. You have seen these results and even performed this operation without knowing it! If you blur, sharper, emboss or add some other simple filter into an image, you are performing convolution with various values. Head to setosa.io site's Image Kernels Explained Visually page and play around with some filters.
Multiple Kernels
Usually, a convolution layer will include multiple kernels. If our input image is sized m x n, the convolution layer will output m x n x K -sized tensor. Remember, tensor is just an n-dimensional matrix. Say that we have K amount of filters, where K = 4, and the input image dimension is 28 x 28 pixels (like the MNIST images), the resulting feature map tensor is 28 x 28 x 4.
The kernel weights are trained as weights for that convolution layer. If each kernel is in the convolution layer is a 3 x 3 kernel, and there are four of those, the amount of weights is: 4 * (3 x 3) = 36 (ignoring the 4 bias terms.) With fully connected layers, we would have had 28 x 28 = 784 weights! (Note: If we have RGB images, this number gets multiplied by 3. That is some amount of weights to be trained!)
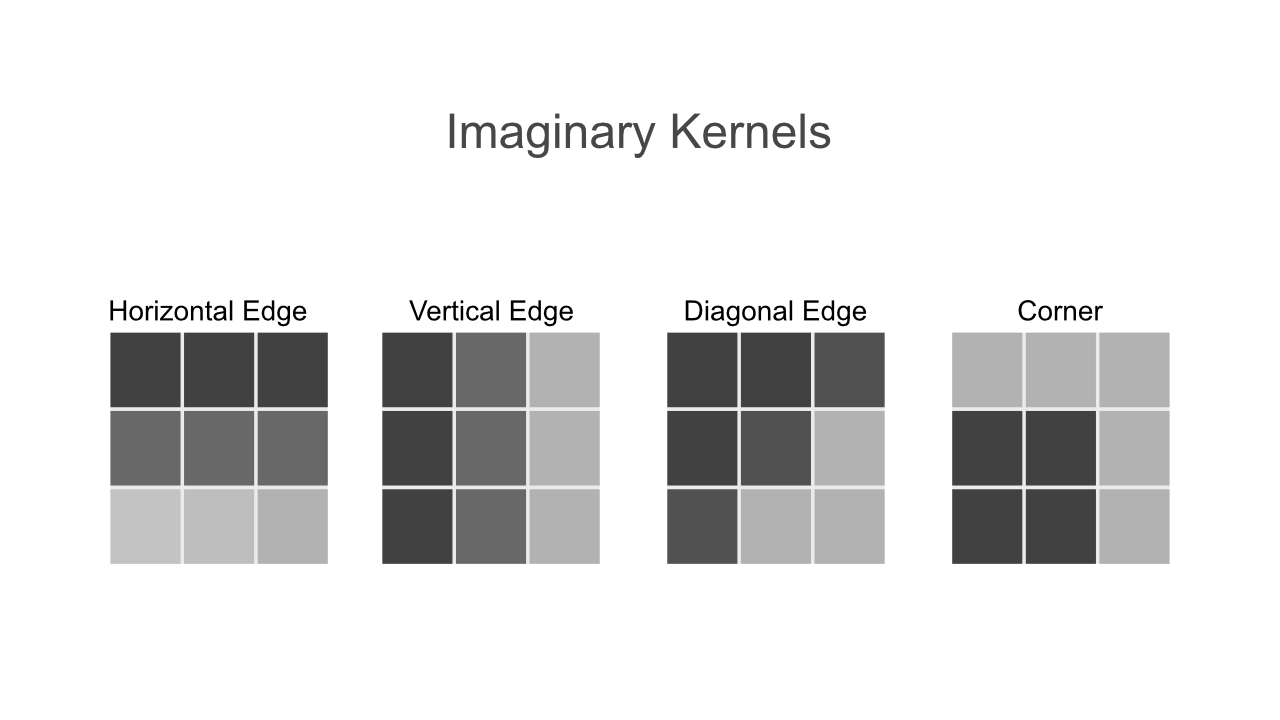
Below, you can see some visual presentations of kernel weights that might have been created during the training. These four kernels would create four feature maps, of which the first would indicate how much a pixel at a given xy-location looks like a horizontal edge. Note that the image is for illustrative purposes and is not accurate in no means.
Multiple Convolution Layers
After performing convolution, the values are run through an activation function (sigmoid, tagitnh, relu…) just as with fully connected layers. We can stack multiple conv layers one after another. The first CONV layers will learn to identify basic structural elements such as edges. The following CONV layers will spawn feature maps based on the previous feature maps, thus being able to handle more abstract shapes and patterns.
In theory, we could stack three convolution layers like this:
INPUT => 3x [CONV => ACT] => FC => FC
In practice, other type of layers such as pool, dropout and batch normalization are needed to both improve the training speed and to limit the dimensions of the layer outputs. Designing CNN architectures is beyond the scope of this course and they require their own sets of books or online courses (such as Deep Learning for Computer Vision by Adrian Rosebrock.)
Usually, a beginner would not create their own architecture anyways. Neural Networks used in different competitions and in research are often shared online, sometimes even pretrained using a given dataset. There are several built-in in the Keras API. Those can be found from the Keras Applications (tf.keras.applications). Before that, let's head to Jupyter Notebook and create a replica of LeNet-5 architecture that should get to roughly 99% accuracywith the MNIST dataset without using data augmentation (according to Yann Lecun's MNIST database website)
Before continuing to the Jupyter Notebook, read the 'Introducing the Convolutional Networks' section from Chapter 6 of the Neural Networks and the Deep Learning online book. Reading the whole chapter is recommended but not required.