What is Machine Learning?
Terms Machine Learning and Artificial Intelligence are often used interchangeably. For marketing and mass media headlines, everything is AI. For academia, ML is often seen as subset of AI.
Recap: Artificial intelligence is a science that tries to construct intelligence (intelligent entities, rational agents). It tries to make a computer behave intelligently (act rationally).
Let's read a couple of definitions of machine learning from literature:
"Machine learning is a field of study concerned with giving computers the ability to learn without being explicitly programmed." - Arthur Smith, 1959.
"A computer program is said to learn from experience, E, with respect to a task, T, and a performance measure, P, if its performance on T, as measured by P, improves with experience E." - Tom Mitchell, 1998.
"A program or system that builds (trains) a predictive model from input data. The system uses the learned model to make useful predictions from new (never-before-seen) data drawn from the same distribution as the one used to train the model. Machine learning also refers to the field of study concerned with these programs or systems." - Google Developers Machine Learning Glossary
By reading the definitions above, you can conclude that machine learning is one of many ways of creating an artificial intelligence system. AI system can be created without ML by using some non-ML methods (for example hard coding or knowledge maps.) Thus, you can have AI without ML, but you cannot have ML without AI. Data science practitioners apply the ML algorithms. Check the Venn diagram below.
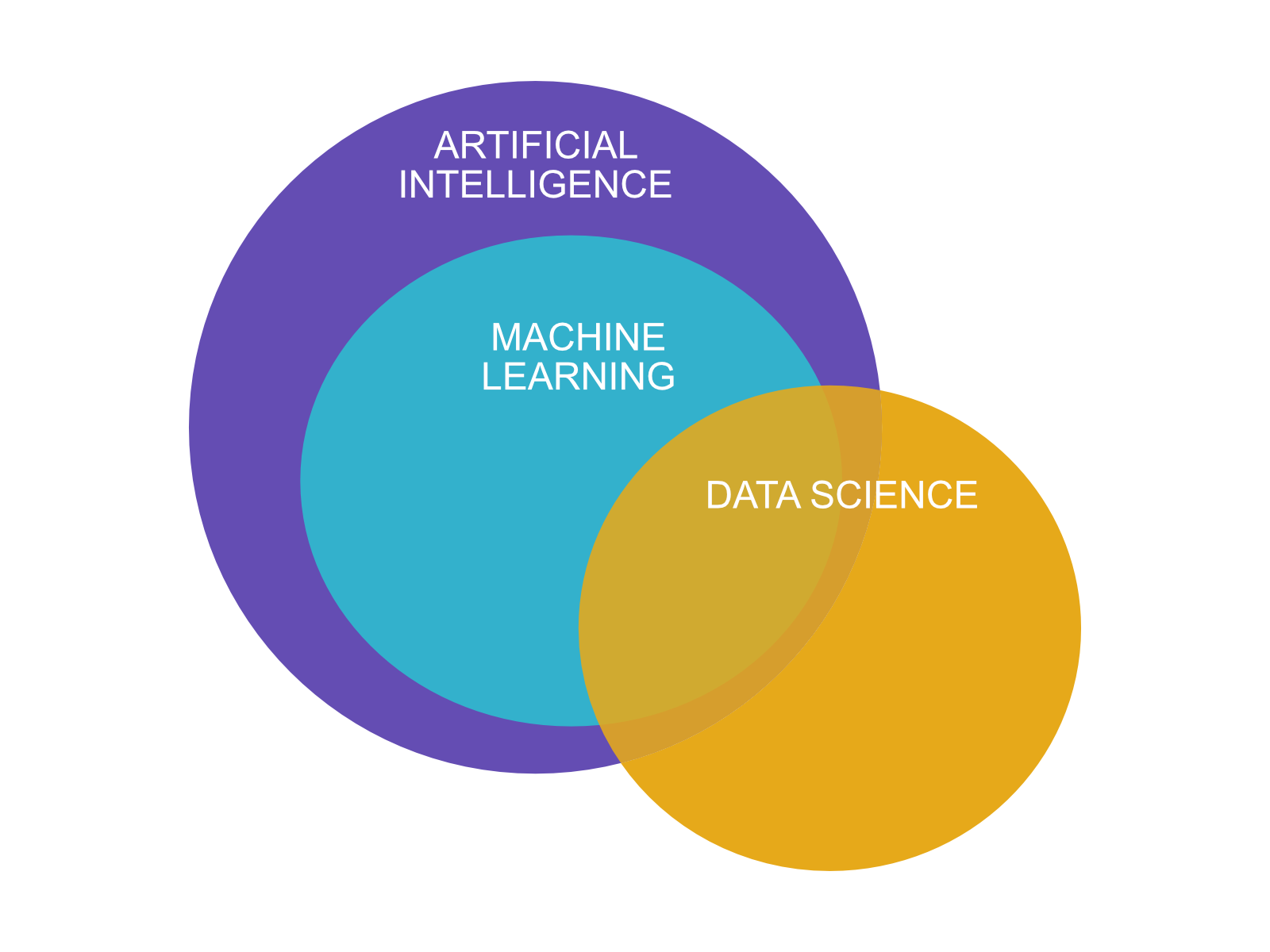
Considering the substantial overlap between definitions of Artificial Intelligence and Machine Learning, it isn't such a surprise that the words are often seen as synonyms.
Why is machine learning used?
In science fiction, AI often has a physical form (e.g. a robot) and can be highly intelligent in similar ways as humans and animals are. Understanding how such a versatile tool would be useful is simple. Current applications of AI are not yet, if ever, on that level. This doesn't stop machine learning from being useful in practical situations.
Imagine that you have been on a vacation and you were the official photographer of the trip. You visited three locations: a forest, a mountain and a museum. In total, you have over 10,000 digital images. Sadly, you made a mistake when copying the images; all 10,000 images are in the same directory "vacationimages". What you would need to do is to split these images into three separate directories: "forestimgs", "mountainimgs" and "museumimgs". When you copied the files, the files were renamed, so the original file names don't exist anymore. Due to a software bug in the camera, GPS data happened to work only in a small portion of the images. These images are easy to find and organize using the GPS data in your favorite photo catalogue app. The rest.. well, organizing them is your problem (task, T).
Here are some options on how to solve the problem (task, T):
Option 1: Do it manually. Go through all the 10,000 images and move them to their correct folders.
Option 2: Program a hardcoded application that separates the images based on rules. Pseudocode of this would resemble this:
procedure classify_image(image)
If image.metadata['GPS'] is None
if image.medianBrightness < threshold
if image.medianColour is in forest_rgb_ranges
# IMAGINE MORE LOGIC HERE
else if image.medianColour is in mountain_rgb_ranges
# IMAGINE MORE LOGIC HERE
Else:
location <- image.metadata['GPS']
if dist(location, forest) < threshold
print "This image has been taken in forest"
else if dist(location, mountain) < threshold
print "This image has been taken on a mountain"
# IMAGINE MORE LOGIC HERE
return prediction
If you look at the example code above, you will notice that you would have to manually tune the parameters such as mountain_rgb_ranges. The images taken in mountains are probably, by average, less green than images taken in the forest. But how much? Hard-coding the logic makes sense only when the problem is fairly easy.
Options 3: Use a machine learning algorithm to classify the images for you. You would train a model using the images that have GPS data. The model would gain experience (E). Performance (P) would be whether the predicted category is correct or not. This process can be seen in the graph below. (NOTE! The green, yellow and blue rectangles represent only the images which have GPS data. All other images of the 10,000 images are left untouched for now, since we don't know where they have been taken.)
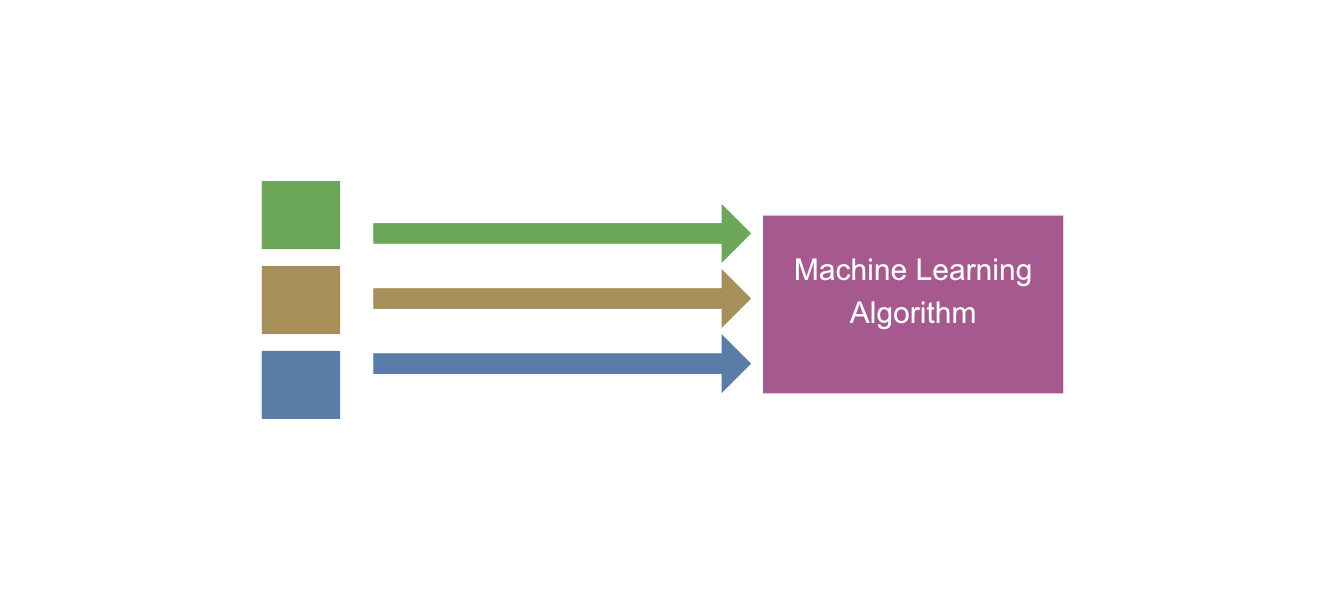
For reference, the features that are used in the training process might include an RGB histogram, exposure information from the camera's metadata, raw pixel values or some other data. Based on the selected features, the model will learn the correlations between the features and the labels. After the training is done, we can use the model to predict the labels of the rest of the 10,000 images. This process, called inference, can be seen in the graph below.
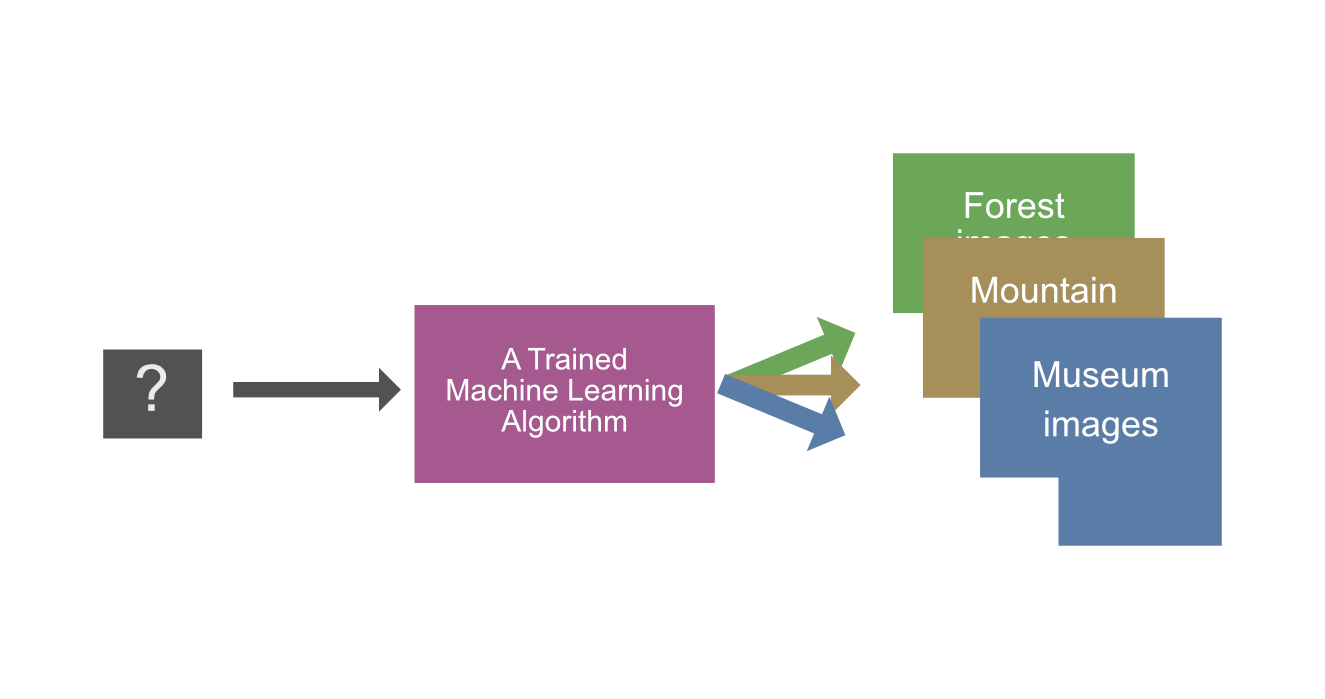
The trained machine learning model doesn't even know what a mountain is; yet, it can label images of mountains in the given dataset. Also, you wouldn't need to manually fine-tune the logic as with option 2.
Task 1
- Browse AI/ML literacy, online videos, news articles about AI/ML. Which term is used and when? And by whom? Or are the terms being used interchangeably?
Hint: Find a medium publication called Towards Data Science. They have separate sections for Data Science, Machine Learning and AI.
Task 2
During this course, some content will be supplemented using a free online book: A Brief Introduction to Machine Learning for Engineers (v3, 2018). The book can be downloaded as PDF from: https://arxiv.org/abs/1709.02840 (2.13 MB.) Download the book and save it so that you can access it again. Then, read pages 6-8.